
Open Console — Data sharing
The core of Open Console manages collected knowledge about websites and domains. This includes (proved) ownership, crawl configuration, blacklist reports, site reviews, and endless possibilities in unexplored territory.
Participants can publish knowledge, and consume knowledge. This needs to be facilitated on an unprecedented scale, which requires new interfacing techniques.
Implementation !!Under construction!!
Context
When reading about the implementation of data-sharing, keep the following rules in mind:
- The website and domain-name owners will be able to see what publishers add about their website/domain. They will be facilitated by an applications (hopefully even competing implementations) which does not differ from other publishers and consumers in the Open Console system. Therefore, they will rarely be mentioned in the following design;
- All interfaces and data exchanges have obligatory access-right checking, with fine-grained rules;
- The data is distributed over a heterogenous environment of large and huge systems;
- Using the data comes with obligations about storage and retention: requires a License (which might get an standardized form).
Challenges
- In a heterogenous environment of large systems, it is impossible to enforce network-wide upgrades, so all must be designed for a gradual upgrade from the start... there is no second chance;
- The communication between the main components easily reaches tens of million facts and many Terabytes per day;
- Failure of any component or connection shall never disturb other components: no central single point of failure;
- The interface to each publishing component will exist in multiple versions: the current (production) version, the next (experimental) version, the next current version (test), and probably some supported older versions. Consumers explicitly switch between versions;
- Participants are legally bound to the rules of the Skrodon Foundation, which enforces EU privacy and GDPR regulation.
Sizing the network
The design must be able to handle the maximum possible data-set, although the first implementations may have modest targets. Which dimensions can we expect?
- 350 million domain names [Verisign 2022Q1]
- 1135 million websites, of which 200 million active [Netcraft August 2022]
- Probably about the same number of people responsible for the websites and domain-names.
- Per entity at least 10kB compressed data.
A simple multiplication results in about 2 billion entities times 10kB is 20 Terabyte of compressed data which has to be shared between Producers and Consumers.
Communicating in the network
Distributing 20 Terabyte of data is no challenge. The problem is querying and updating that amount of information. For instance, a web crawler will need information about the websites it crawls, but will also produce information about the results of its activities. For all Publishers and Consumers, this leads to tens of thousands of queries and tens of thousands of updates per second. Really expensive and fragile to implement with a database of 2 billion complex objects.
It is important to realize that Consumers may prefer to get their data on request, but that real-time access performance to the whole data-set is avoidable. When algorithms are used which use batch processing, implementation becomes affordable and flexible. This approach is orthogonal to the micro-services ideology (with many short connections between specialized data sources); let's call it macro-services for now.
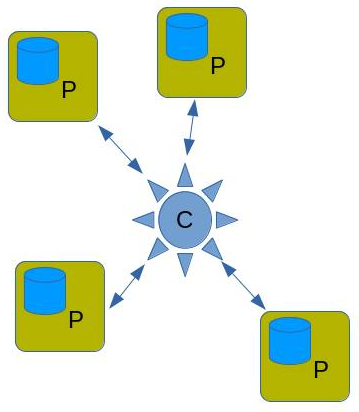
In the picture in the left, the Consumer and Producers are managed separately: there is no (lawful) way to implement it as a single instance, because the data is owned by different organizations.
In any communication model, the Consumer/Client (C) requests data from the Producer/Service (P). The common dogma is to let the Consumer request items from the (external) Producers on demand —leading to at least one request per produced item—: micro-services. This is concept is not usable with the amount of items Open Console needs to exchange: servers cannot handle the expected billions of requests per day.
Using the fact that Consumers do not require real-time performance, the request can get split between what you need and when you get it. Each of the producers share information in bulk: you may want genericly produced data (also available to other Consumers), or data grouped following agreed rules pre-configured for you. On the moment that the Consumer has processing capacity available, it will fetch the requested data in bulk which the producer composed when it had resources to do it.
Bulk transport of data
Two common ways of bulk transport of data are via ftp-servers and by using shared disks. The former is traditionally used to transport large archives of items, for instance software released in a Linux distribution. Any kind of access control is hard to achieve with ftp-servers. Also, ftp does not implement management of publication archives, which makes it a hassle when there are hundreds of Publishers with their own servers.
Using a shared disks (for instance "in the cloud") improves access control. Still, this also does not support publication management.
As far as we know, there is only one communication system powerful enough: Meshy Space (under development)
Bulk transport over Meshy Space (MS)
In Meshy Space, Publishers manage Collections, which resemble sub-sets of ftp-server data. The Collection contains Units of strongly related data, which a fine grained access- and lifespan control. You can easily sub-set and super-set collections.
Collections have a simple mirror mechanism, which can be configured as cache to Consumers. Transport of Units between servers is transparent and optimal, like shared disks.
Using MS, a Producer uploads Units of information in its local Collection. When the Consumer refreshes its view on the collection, it will get all changed Units in bulk. These changes will make processing happen on the Consumer via Triggers. These synchronization moments typically happen every hour or less.
Consumer processes
This design focuses on situations where Consumers process huge quantities of Producer data. Of course, this will work for smaller consumptions as well. This design uses the Meshy Space Concept for communication.
The Consumer implements a Task. These Tasks combine information from one or more (external) Producers with data it has collected by itself. The Consumer's Task connects to the data Collections which are published by the Producers.
On regular intervals (typically one hour), the Producer releases a new version of its Collection. All Consumers which need that Collection get informed and bulk-download the changes: modifications made to the Units in the Collection. The Consumer processes the changes according to the Task it has to fulfill. The Consumer may decide to cache processed Units, or drop them once used.
The Consumer may publish its results as Units in its own Collections; it may be a Producer by itself. However, a Consumer may also keep its results for its own use only.
Example in Open Console
One visible exponent of the Open Console network will be the user interface for website owners. There will be multiple implementations for this user interface. Each implementation is a Consumer, in the sense as described on this page.
User will register at the Open Console website, and from then on, that website will start keeping track on where the user's website is being mentioned. To achieve this, it connects to publishers of website related data (getting a License to access and process that data). Some data will be available immediately, where other facts will appear over time.
Most publications will contain Presentation details: show forms which will help displaying and updating the data (Units). They will also support translation and documentation.
The Open Console website lets the user pick from the publications which it has licensed. It displays the retrieved data using the provided forms, in its own style and structure.